






بخشی از پاورپوینت
--- پاورپوینت شامل تصاویر میباشد ----
اسلاید 1 :
معرفی
الگوريتم های داده كاوی
معرفی قانون كاوی
معرفی خوشه يابی
معرفی كلاس بندی
اسلاید 2 :
تلاش انسان از ابتدا برای تحليل مشاهدات
افزايش حجم اطلاعات
كتابخانه های الكترونيكی
اينترنت
اطلاعات مالی و سپرده گذاری و تجارت و ..
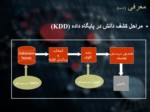
كشف دانش در پايگاه داده ها (KDD)
اسلاید 3 :
Data warehousing : به فرایند جمع آوری و تمیز كردن دادهای تراكنش ها و مهیا كردن آن برای آنالیز و سیستم های پشتیبان تصمیم می باشد.
انتخاب و پيش پردازش اوليه : فرآيند بهبود كيفيت داده های موجود بر اساس روش های زير:
تميز كردن داده ها به منظور نرمال سازی ، خارج كردن نویز ، كنترل داده هاي گم شده ، كاهش redundancy و غیره
Data Integration : شامل يكي كردن داده های جمع آوری شده از چند منبع غیر همگن.
Data Reduction and Projection: انتخاب جزییات مفید كه نشان دهنده داده های ما باشند، كه معمولا" با توجه به كاري كه مي خواهیم انجام دهیم صورت مي گیرد.
توصیف و ترجمه : شامل Visualize كردن و توصیف الگو های كشف شده می باشد.
تصديق درستی
اسلاید 4 :
مدل : تابع مدل Model Function)) و فرم نشان دادن (Representational form) آن مدل شامل پارامتر هایی است كه باید از داده ها با توجه به تابع انتخاب شده و به وسیله فرم یا ابزار نشان دادن محاسبه شوند.
شرایط دلخواه : یك پایه برای برتری دادن یك مدل يا مجموعه پارامتر ها بر دیگری بر اساس داده ها.
الگوریتم جستجو : مشخصات يك الگوریتم جستجو برای پیدا كردن یك مدل ، الگو یا پارامترهای خاص با داده ، مدل ها ، و شروط داده شده است.
اسلاید 5 :
كلاس بندی (Classification): تابع مدل یك آيتم داده ای را در یك سری كلاس های از پیش تعریف شده كلاسه بندی می كند. (Supervised Learning)
رگرسيون (Regression): قصد این تابع تصوير كردن یك آيتم داده به یك مقدار واقعی پیش بينی است.
خوشه يابی(Clustering): يك آيتم داده ای را به یكی از چند خوشه تصوير می كند كه اين خوشه ها گروه های طبیعی هستند كه بر اساس مثلا" متريك های شباهت ايجاد شده اند. هدف اصلی پيدا كردن نظم در داده ها مي باشد. (Unsupervised Learning)
توليد قانون (Rule Generation):
Association rule mining and Dependency modeling كه دومی به كشف وابستگی های قوی بین متغیر ها به كار مي رود.
اسلاید 6 :
خلاصه و فشرده سازی (Summarization and condensation): یك توصیف فشرده از داده ها به ما می دهد.
آناليز دنباله ها (Sequence Analysis): الگو های دنباله مثل سريهای زمانی را مدل می كند.
مثال :
كشف آنومالی در سيستم
پيش بينی وضع هوا
تشخيص تومور در عكس های مغزی
اسلاید 7 :
هدف اصلی :پيدا كردن قوانين منطقی كه بر داده ها حاكم می باشد
روش های اصلی :
Association Rule Mining : به صورت عبارت هایي است به شكل X=>Y كه X و Y زیر مجموعه از تمام ویژهگيها هستند. و این ادعا با درجه اعتبار بزرگتر از c درست باشد.
Classification Rule Mining: يك پروسه كنترل شده كه از يك سری مجموعه داده برای آموزش استفاده می كند و هدف پيدا كردن قوانين در داده هابه منظور پيش بينی كلاس از پيش تعريف شده برای يك سری داده تستی می باشد
Dependency Rule Mining : يك پروسه كنترل شده است كه ویژهگيها را به دو قسمت هدف و غیر هدف تقسيم مي كند و قسمت غير هدف فقط می تواند در قسمت شرط باشد ولی به دنبال قوانينی هستيم كه شامل ويژهگيهای هدف باشد.
اسلاید 8 :
هدف اصلی :كاهش فاصله بين بردار های داخل يك خوشه و افزايش فاصله بين خوشه ها می باشد.
چالش های اصلی: انتخاب تعداد خوشه مناسب ، تعريف معيار فاصله و تشخيص خوشه هايی كه شكل منظم ندارند ، می باشد.
انواع برخورد ها :
Partial)Sequential): یك بخش اولیه درست می كند و بعد بوسیله از روشهای تكرار شونده براي بهينه كردن هدف كار استفاده می شود.
Hierarchical : بدين صورت كه ابتدا كل داده ها را در يك خوشه قرار می دهد سپس اين خوشه را در چند گام می شكند تا به n كلاستر برسد.
بر اساس بهينه سازی : روش های K-Means و توابع Density
اسلاید 9 :
هدف اصلی :پيدا كردن روشی خاص و پارامترهای روش به گونه ای كه علاوه بر خطای كم قابليت عمومی شدن را نيز داشته باشد.
روش های اصلی در كلاس بندی :
درخت تصميم : فضاي تصميم را به تكه هاي ثابت مي شكند.
Probabilistic or Generative Model : از روش های آماری معمولا“ مبتنی بر تئوری Bayes استفاده می شود.
Nearest Neighbor Classifiers: كمترین فاصله را نمونه ها نشان دسته (Prototype) ها محاسبه می كند.
رگرسيونی : مي تواند چندجمله ای باشد مثلا“ شكل : aX1+bX2+c=Ci باشد.
اسلاید 10 :
ادامه روش های اصلی در كلاس بندی:
شبكه های عصبی : يكی از پركاربردترین روشهای محاسبات نرم ( Soft Computing) ساختار ANN شامل يك سری گره می باشد كه با تعدادی رابط جهت دار به هم متصل مي باشند. خروجی تمام گره های شبكه خاصيت بستگی به يك سری پارامتر قابل تغيير مرتبط به اين گره ها دارد.
شبكه های RBF : از مدل هاي عمومی تشخيص تابعی كه در كلاس بندی نيز استفاده مي شود. خصوصيات نزديك به شبكه های عصبی دارد ولی از نظر رفتار شفاف تر است.
Support Vector Machines : ايده اصلي اين است كه با يك تصويرغير خطي داده هايی را كه نمي توان با يك مرز تصميم خطي در فضاي خصوصيات جدا كرد را به فضايي با بعد بالاتر ببرد كه در اين بعد به توان يك مرز تصميم خطي براي داده ها رسم كرد.
