










بخشی از پاورپوینت
--- پاورپوینت شامل تصاویر میباشد ----
اسلاید 1 :
مقدمه
lSVM دسته بندی کننده ای است که جزو شاخه Kernel Methods دریادگیری ماشین محسوب میشود.
lSVMدر سال 1992 توسط Vapnik معرفی شده و بر پایه statistical learning theory بنا گردیده است.
lشهرت SVM بخاطر موفقیت آن در تشخیص حروف دست نویس است که با شبکه های عصبی بدقت تنظیم شده برابری میکند: 1.1% خطا
l
اسلاید 2 :
lهدف این دسته الگوریتم ها تشخیص و متمایز کردن الگوهای پیچیده در داده هاست ( از طریق کلاسترینگ، دسته بندی، رنکینگ، پاکسازی و غیره)
lمسایل مطرح:
lالگوهای پیچیده را چگونه نمایش دهیم
lچگونه از مسئله overfitting پرهیز کنیم
اسلاید 3 :
ایده اصلی
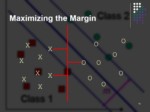
lبا فرض اینکه دسته ها بصورت خطی جداپذیر باشند، ابرصفحه هائی با حداکثر حاشیه (maximum margin) را بدست می آورد که دسته ها را جدا کنند.
lدر مسایلی که داده ها بصورت خطی جداپذیر نباشند داده ها به فضای با ابعاد بیشتر نگاشت پیدا میکنند تا بتوان آنها را در این فضای جدید بصورت خطی جدا نمود.
l
l
اسلاید 4 :
تعریف
lSupport Vector Machines are a system for efficiently training linear learning machines in kernel-induced feature spaces, while respecting the insights of generalisation theory and exploiting optimisation theory.
lCristianini & Shawe-Taylor (2000)
اسلاید 5 :
مسئله جداسازی خطی:
Linear Discrimination
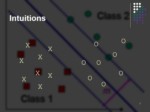
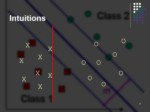
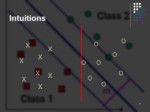
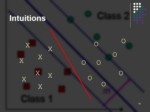
lاگر دو دسته وجود داشته باشند که بصورت خطی از هم جداپذیر باشند، بهترین جدا کننده این دو دسته چیست؟
lالگوریتم های مختلفی از جمله پرسپترون میتوانند این جداسازی را انجام دهند.
lآیا همه این الگوریتمها بخوبی از عهده اینکار بر میآیند؟
اسلاید 6 :
Intuitions
اسلاید 7 :
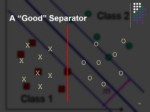
A “Good” Separator
اسلاید 8 :
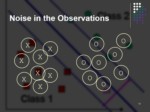
Noise in the Observations
اسلاید 9 :
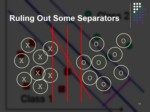
Ruling Out Some Separators
اسلاید 10 :
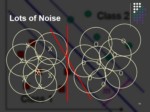
Lots of Noise
