



بخشی از پاورپوینت
--- پاورپوینت شامل تصاویر میباشد ----
اسلاید 1 :
موتور جستجو(Search Engine)
برنامه هایی که موضوعات مورد نظر کاربران را در قالب کلمات کلیدی، درون اسناد و اطلاعات موجود در اینترنت کاوش و نتایج را در قالب «آدرس محل ذخیره» عرضه میکنند.
خاص منظوره: برای جستجو در یک برنامه کاربردی(سایت) خاص
موتورهای جستجوی جهانی(معمول): کلیه اسناد موجود در اینترنت را بررسی می کنند
سوپر موتورهای جستجو: درخواست های کاربران را در موتورهای مختلف دنیا جستجو و نتایج حاصله را ترکیب می کنند
اسلاید 2 :
انواع موتورهای جستجو بر اساس نحوه عملکرد
مبتنی بر خزش – Crawler based Search Engines
مبتنی بر فهرست – Directory based Search Engines
با دخالت مستقیم صاحبان اسناد
به صورت درختی به زیر شاخه های مرتبط دسته بندی می شوند
برای حفظ جایگاه، صاحبان اسناد باید توجه ویژه ای به کیفیت و محتوای صفحاتشان داشته باشند.
با توجه به دسته بندی هوشمندانه معمولا نتایج سودمندتری ارائه می دهند
ترکیبی - Hybrid Search Engines
اسلاید 3 :
صفحات وب درحال تغییر
تقریبا 40% صفحات وب .com روزانه تغییر می کنند.
نیمه عمر وب سایت های .com 10 روز است!!
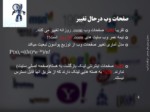
مدل آماری تغییر صفحات وب از توزیع پوآسون تبعیت میکند
P(n)t=((λt)ne- λt)/n!
22% صفحات اینترنتی لینک بازگشت به هسته(صفحه اصلی سایت) ندارند. 20% به هسته هایی لینک دارند که از طریق آنها قابل دسترس نیستند.
اسلاید 4 :
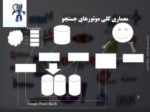
معماری کلی موتورهای جستجو
اسلاید 5 :
ماژول خزنده - Crawler
وظیفه: استخراج صفحات و ذخیره آنها در انباره صفحات
با یک مجموعه اولیه از URLها که در یک صف اولویت دار قرار دارد شروع می کند.
پس از استخراج صفحات همزمان با ذخیره آنها، لینک های درون آنها را برای اضافه شدن به صف تحویل ماژول کنترل کننده خزش می دهد.
کنترل کننده آدرس های تکراری را از این مجموعه حذف و بقیه را درصورت داشتن معیارهای لازم به ترتیب اولویت به انتهای صف اضافه میکند
اسلاید 6 :
معیارهای اولویت صفحات
مبتنی بر گرایشات کاربران – Interest Driven
مبتنی بر شهرت - Popularity Driven
مبتنی بر محل قرار گرفتن صفحات – Location Driven
اسلاید 7 :
Interest Driven
اسلاید 8 :
Popularity Driven
Back link count: یکی از راههای اندازه گیری شهرت صفحه، شمارش تعداد صفحاتی است که به آن لینک داده اند. هرچه این تعداد بیشتر باشد نشان دهنده شهرت بیشتر صفحه است.
اسلاید 9 :
Location Driven
فاکتورهای زیر می توانند برای مشخص کردن فاصله صفحات استفاده شوند
محل قرار گرفتن آدرس صفحه
فاصله آن تا صفحه اصلی سایت(تعداد لینک)
آدرس صفحه
ماهیت آدرس (.net, .com,..)
اسلاید 10 :
الگوهای کاوش ماژول خزنده
خزش و توقف – Crawl & Stop: با شروع از یک آدرس دقیقا k صفحه را(به ترتیب اولویت) استخراج میکند و خارج می شود
خزش و توقف با آستانه – Crawl & Stop with Threshold: با شروع از یک آدرس تمام صفحاتی را که اولویتشان از حد آستانه بیشتر است ملاقات می کند
