



بخشی از مقاله
*** این فایل شامل تعدادی فرمول می باشد و در سایت قابل نمایش نیست ***
تشخیص پولشویی درسیستم بانکی با استفاده از الگوریتم ژنتیک و شبکه عصبی
چکیده
امروزه مجرمان از طریق ارتکاب اعمال مجرمانه میکوشند در فاصله زمانی کوتاه، ثروت هنگفتی تحصیل کنند و مبنای پولشویی را در جرمی مثل سرقت، به واسطه درآمدی که برای سارق دارد، ایجاد میکنند، به گونهای که پس از ارتکاب جرم و تحصیل ثروت، در پی پوشاندن اعمال غیرقانونی خود، پول کثیف تحصیل شده را با ترفندهایی، قانونی نشان میدهند و سعی میکنند تا مقامات قضایی و انتظامی و مسئولان ذیربط از توقیف اموال بیخبر بمانند و در نتیجه، موجب تضعیف دولت، افزایش تورم و نابسامانی اقتصاد و بازار میگردند. از این پدیده، امروزه به »پولشویی« تعبیر میشود. یکی از بزرگ ترین بنگاه های اقتصادی هر کشوری که مورد سوء استفاده مجرمان به منظور پولشویی قرار می گیرد بانک ها می باشند که بزرگترین ضربه را به اقتصاد یک کشور وارد می کند. در این مقاله روشی برای تشخیص حساب هایی که از آن ها در سیستم بانکی به منظور پولشویی استفاده می شود طرح شده است. به علت وجود داده های زیاد در بانکها داده کاوی تاکنون کاربردهای زیادی در امور مالی و پولی داشته است. پس در ابتدا با استفاده از الگوریتم ژنتیک شاخص ترین ویژگی های حساب های بانکی که بیشترین تاثیر در عمل پولشویی دارند و به گونه ای الگوهای رفتاری پولشویان را نشان می دهد استخراج شود و سپس ویژگی های استخراج شده به همراه رکوردهای داده را به یک شبکه عصبی مصنوعی به منظور یادگیری و ساخت مدل تشخیص پولشویی می دهیم. ما مدل طراحی شده را با استفاده از یک مجموعه داده معتبر که توسط دانشگاه کالیفرنیا ایرواین2 ارائه شده است ارزیابی نموده و با سایر روش هایی که به منظور تشخیص در حوزه کلاهبرداری بانکی بر روی این مجموعه داده مدل سازی شده اند مقایسه می نماییم. از آنجایی که در فرآیند های تشخیص مهمترین معیار، دقت تشخیص است نتایج بدست آمده نشان داد که این مدل از نظر صحت تشخیص نسبت به سایر روش های مدل سازی جهت تشخیص بر روی این مجموعه داده با 90.61 درصد دارای عملکرد بالاتری است.
-1 مقدمه
شاید اغراق نباشد که بگوییم از بدو خلقت انسان بر این کره خاکی، او همواره به دنبال کسب درآمد تملک و افزایش سرمایه های مادی بوده و شاید بتوان گفت که برای نیل به آن، در حالت کلی دو راه پیش رو داشته و دارد
• از راههای مشروع و متناسب با قانون و هنجارهای آن جامعه
• از راههای نامشروع
انسان های زیاده خواه اغلب به جهت آسانتر بودن، پردرآمد بودن و سرعت بیشتر اعمال مجرمانه در کسب درآمد، از راه نامشروع وارد شده اند که همواره این گونه حرکات مشکلاتی را برای سایرین و از جمله، جامعه در برداشته است و همواره سعی بر این بود که با اتخاذ تدابیر لازم از این گونه جرایم که محل آسایش، رفاه امنیت و ... در جامعه می گردد جلوگیری نماید. رشد پدیده پولشویی تا حدی ناشی از گسترش انواع پول و معاملات فرا مرزی، ساده تر شدن تکنیک ها و تجهیزات در موسسات مالی و بانکی برای انتقال پول، پیچیدگی رو به تزاید و خصوصیت داد و ستدها است. هر چه جهانی شدن و ادغام اقتصاد بین المللی افزایش می یابد، از موانع آزاد سرمایه و نقدینگی کاسته شده و سرعت انتقالات الکترونیکی بافرصت های تجاری جدید ترکیب می شود، درعین حال امکان پنهان کردن منافع حاصل از فعالیت های مجرمانه و شبکه های اقتصاد زیر زمینی نیز آسان تر صورت می گیرد. پول شویی آثار زیان بار غیرمستقیمی هم دارد؛ زیرا داد و ستدهای غیرقانونی، بازدارنده تبادلات قانونی نیز هست؛ برای مثال داد و ستدهای ارزی قانونی، موردی، بر اثر آن که با پول شویی همراه شود، مطلوبیت ندارد. مهم تر از آن، مبادلات زیر زمینی، فساد و اختلاس، از اطمینان و اعتماد به بازار و سازوکارهای آن می کاهد. ذخیره (مانده) انباشت دارایی های ثباتی اقتصادی را افزایش می دهد(.(R. Milne:2013
مشاغلی که در معرض سوء استفاده پولشویان قرار می گیرد عبارتنداز سیستم بانکی، صرافی ها، دفاتر اسناد رسمی، آژانس های مسافرتی و شرکت های حمل و نقل، عرضه کنندگان کالاهای گران قیمت و شرکت های بیمه می باشد. مهمترین هدف آرمانی مقاله شناسایی حساب هایی که در سیستم بانکی از آن ها به عنوان پولشویی استفاده میشود که در کنار این هدف، اهداف زیر هم مد نظر می باشد:
· شناسایی افرادی که از طریق سیستم بانکی فرار مالیاتی انجام میدهند.
· شناسایی پول های کثیف و نامشروع از پول های تمیز و حلال که وارد سیستم بانکی کشور گردیده است.
· پولشویی یک جرم ثانویه می باشد که منشا اصلی جرم که منافع و درآمد از طریق آن حاصل شده است را پنهان میکند که با انجام این تحقیق باعث آشکار شدن جرم اولیه می گردد.
مقاله ارائه شده در ادامه به شرح زیر است: بخش2 ارائه خلاصه ای از کارهای انجام شده است. در بخش3 مدل ارائه شده و جزئیات آن شرح داده شده است.. در بخش 4، نتایج به دست آمده از مدل ارائه شده بر روی مجموعه داده ذکر شده، نشان داده و با سایر روش های موجود مورد مقایسه قرار گرفته است.
-2 کارهای انجام شده
در سال 2015، اشکان زکریازاد و اکرم دومان یک روش بر مبنای شبکه عصبی مصنوعی جهت تشخیص کلاهبرداری در سیستم بانکی ارائه دادند که بر روی یک مجموعه داده با نظارت، ویژگی مربوط به تراکنش های مشتری مورد مدل سازی قرار گرفت. در سال 2014، هارمت کور خانوجا Harmeet Kaur) (Khanuja:2014,pp201-210یک متدولوژی قانونی برای بانک های خصوصی نشان داد، که شامل نظارت بر روی تراکنش های حسابرسی شده هر بانک تحت نظر بانک مرکزی هند((RBI بود و یک دستور العمل جهت تولید گزارش برای تراکنش های مشکوک ارائه داد. در سال 2014، ماهش خاروت((Mahesh Kharote:2014 ، با استفاده از آنالیز دنباله تراکنش ها و آنالیز رفتار مشتریان به منظور تصمیم گیری در مورد اینکه یک مشتری مشکوک است یا نه ارائه داد. در سال 2010، اسماس آریک (Asma S. Larik:2010)یک رویکرد تشخیص ناهنجاری که با استفاده از خوشه بندی برای شناسایی مشتریان رفتار طبیعی و روش های آماری برای تعیین انحراف از یک تراکنش خاص از رفتار گروه مربوطه ارائه شده است.
در جدول شماره -1 به صورت فشرده رویکردهای متفاوت، جهت مقابله با پولشویی نشان داده شده است.
یکی از آخرین روشهایی که به منظور تشخیص کلاهبرداری در سیستم بانکی مورد استفاده قرار گرفته که از نظر صحت تشخیص از روش هایی که تا کنون معرفی شده بالاتر است مقاله ای است که مبنای مقایسه این تحقیق قرار گرفته با عنوان "کاربرد شبکه عصبی بهبود یافته برای تشخیص تقلب و بازاریابی مستقیم" . (A. Zakaryazad and E. Duman:2016) که این مقاله در اکتبر 2015 مورد تایید قرار گرفته و در ژانویه 2016 به چاپ می رسد. در این روش تشخیص با استفاده از تغییراتی که به به منظور بهینه کردن شبکه عصبی مصنوعی به وجود آمده این روش را به همراه سایر روش های تشخیصی که تا کنون معرفی شده اند بر روی مجموعه داده" " Bank Marketing که بر روی سایت UCI قرار دارد اجرا شده و مورد مقایسه قرار گرفته اند که در جدول شماره 2 نشان داده شده است.
-3 متدولوژی
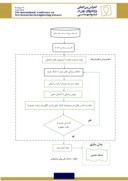
در شکل1 فلوچارت کامل روش پیشنهادی نشان داده شده است. در ابتدا داده های مربوط به حساب های بانکی مشتریان که شامل تراکنش های حساب و مشخصات فردی مشتریان می باشد در فاز اول پیش پردازش قرار می گیرد تا داده های خالی و نویز در این فاز حذف شوند. سپس ما به دنبال الگوهای رفتاری پولشویان هستیم و با توجه به اینکه داده های ما برچسب دار هستند برای بدست آوردن این الگوها باید ویژگیهایی که بیشترین تاثیر را در انجام پولشویی دارند و به ما در تشخیص پولشویی کمک می کنند را شناسایی کنیم برای انجام این کا از الگوریتم ژنتیک استفاده کردیم درادامه توضیح کامل تری ارائه می دهیم. پس از آماده سازی داده هاو استخراج ویژگی های موثر داده های بدست آمده را به کمک شبکه عصبی مدل سازی می نماییم. در نهایت پس از آموزش مدل و تست آن میزان دقت روش را محاسبه و با روش های مشابه مقایسه می کنیم.
-1-3 تابع برازش3
پس از انتخاب تصادفی والد و با یک احتمال تصادفی عمل ترکیب و جهش انجام شد حال فرزند تولید شده به منظور اینکه مناسب و سازگار با جمعیت اولیه باشد توسط تابعی به نام تابع برازش یا تابع ارزیابی فرزند تولید شده ارزیابی می شود تا در صورتی که فرزند مناسبی از نظر انتخاب ژن ها و همچنین مناسب با هدف تکامل جمعیت می باشد آن را به جمعیت اولیه اضافه کند در غیر این صورت رد کند. اطلاعات مورد نیاز برای کلاسه بندی یک تاپل در D برابر فرمول زیر است:
که در آن pi احتمال آن است که یک تاپل دلخواه در D متعلق به کلاس Ci باشد که این احتمال به صورت تخمین زده میشود ( تعداد تاپلها در را نشان میدهد ) . تعداد کلاسهای موجود m است . در واقع Info(D) همان entropy میباشد. فرض میکنیم صفت A دارای v مقدار متمایز بصورت باشد یا بعبارت دیگر A یک صفت گسسته است . اگر بخواهیم D را بر حسب صفت A بشکافیم v بخش یا زیرمجموعه مانند حاصل می شود که در آن شامل تاپلهایی از D است که مقدار صفت A در آنها برابر است . اگر فرض کنیم که D در گرهای چون N قرار داشته باشد آنگاه این بخشها متناظر با شاخههایی هستند که از N خارج میشوند . اطلاعات مورد نیاز برای کلاسهبندی یک تاپل از D بر حسب صفت A برابر :
است . عبارت در واقع وزن بخش j را نشان میدهد .
اطلاعات حاصل از انشعاب بر حسب صفت A را به صورت زیر تعریف میکنیم :
هر چه مقدار بهره صفت ( Gain(A) ) A بیشتر باشد یا به عبارت دیگر هر چه InfoA(D) کمتر باشد صفت A به عنوان صفت شکاف انتخاب می شود.
تابع برازشی که ما برای انجام روش پیشنهادی انتخاب کردیم درخت تصمیم می باشد و هر فرزند که تولید شد به کمک درخت تصمیم که توضیح دادیم ارزیابی شده و مقدار صحت سازگاری فرزند تولید شده را بر می گرداند.در واقع درخت تصمیم یک رشته کروموزومی را دریافت کرده مقدار آنتروپی تک تک ژن ها را به کمک فرمول هایی که پیش تر توضیح دادیم بدست آورده در نهایت با توجه به آنتروپی کل جمعیت Information Gain را محاسبه می نماید و درصد بدست آمده از Information Gain را بر می گرداند و به اینصورت آن صحت و مناسب بودن فرزند نسبت به جمعیت اولیه ارزیابی می شود.
-2-3 استخراج ویژگی با الگوریتم ژنتیک
فرآیند استخراج ویژگی به کمک الگوریتم ژنتیک را در قالب یک مثال توضیح می دهیم. فرض کنید یکسری متغیر (شکل 6-4 )یا ویژگی A,B,C,D,E,F,G,H,…. در مجموعه داده داریم. اولین کاری که انجام می دهیم اگر تعداد متغیر ها زیاد بود با یک احتمالی مثلا 0.4 یا 0.5 یعنی 40 درصد یا 50 درصد از ویژگی ها را برای والدین انتخاب می کنیم که برای مثال 2 والد انتخاب شد در والد اول در رشته کروموزومی ژن های A,D,E و در والد دوم ژن های کروموزومی C,H,J انتخاب شده است همانطور که در شکل2 مشخص است والد اول ژن A را دارد ولی مقدارش صفر است و بالفعل نشده و ژن های D,E فعال دارد و والد دوم هر سه ژن فعال هستند. حال مرحله اول الگوریتم ژنتیک عمل ترکیب یا Cross Over اتفاق می افتد که اینجا با احتمال 1/3 این عمل را انجام دادیم یعنی اگر 3 تا ژن داریم یکی از آنها را از هر کدام از والدین جدا کن و به والد دیگری بچسبان. الان همانطور که در شکل6-4 مشخص است در عمل ترکیب متغیر A از والد اول جدا شده و با والد دوم ترکیب شده و متغیر C با والد اول ترکیب شده است. حال وارد مرحله جهش یا Mutation می شویم در این مرحله باز با یک احتمالی مثلا 1/3 عمل جهش را انجام می دهیم یعنی اگر سه تا ژن داریم یکی از سه ژن را عمل جهش را انجام بده که در والد اول
