




بخشی از پاورپوینت
--- پاورپوینت شامل تصاویر میباشد ----
اسلاید 1 :
More on B+Trees
نگاهداري يک ايندکس SimplePrefixB+tree چگونه است؟
شرايط انتخاب اندازه هر بلوکIndex Setچگونه است؟
ساختاريک ايندکس Variable-Order B+tree چگونه است؟
مزايا و معايب Variable Order B+Tree کدامند؟
روش بهينه ايجاد ( loading) يک B+Tree چگونه است؟
خواص مشترک انواع B-Tree و B+Tree کدامند؟
اسلاید 2 :
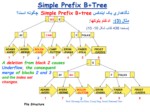
Simple Prefix B+Tree
نگاهداري يک ايندکس SimplePrefixB+tree چگونه است؟
مثال (1):حذف رکوردها:
(صفحه 436 کتاب شکل 8- 10)
اسلاید 3 :
انتخاب اندازه بلوکهاي Index Set
شرايط انتخاب اندازه هر بلوکIndex Setچگونه است؟
چرا بهتر است که اندازه بلوکهاي index set برابر با اندازه بلوکهاي sequence set باشد؟
انتخاب اندازه بلوکهاي sequence set با در نظر گرفتن عواملي بوده است که در تعيين index set نيز همانقدر اهميت دارند، مثل:
qظرفيت حافظه RAM و
qمشخصات مربوط به ديسک ها.
استفاده از بافرهاي مشترک براي نگهداري بلوکها در حافظه (Caching) ساده تر ميشود. (چرا؟)
بلوکهاي ايندکس و داده مي توانند در يک فايل ذخيره شده و به يکديگر نزديکتر باشند. (چرا؟)
اسلاید 4 :
Variable-Order B+Tree
ساختاريک ايندکس Variable-Order B+tree چگونه است؟
نوعي B+Tree که در آن:
(1 ظرفيت (order) نودهاي ايندکس متغير ميباشد و
(2 اطلاعات موجود در اين نودها حتي الامکان فشرده شده ميباشد.
اسلاید 5 :
ساختاريک ايندکس Variable-Order B+tree چگونه است؟
در اين ساختار:
فضاي موجود براي نگهداري separator ها بطور کامل استفاده شده است.
ايندکس مربوط به separator ها امکان جستجوي دودويي را ميدهد.
بلوکها بوسيله (Relative Block Number) بطور مستقيم قابل آدرس دهي هستند.
اسلاید 6 :
Variable-Order B+Tree
ساختاريک ايندکس Variable-Order B+tree چگونه است؟
مثال: (صفحه 445 کتاب شکل 10.15 )
اسلاید 7 :
Variable-Order B+Tree
مزايايVariable Order B+Tree کدامند؟
درجه يا order ايندکس به ماکزيمم ممکن ( با توجه به اندازه بلوک ) رسيده و
عمق درخت ( depth ) به مينيمم ممکن خود ميرسد و
بنابراين در تعداد I/Oصرفه جويي ميشود. ( seek )
معايب Variable Order B+Tree کدامند؟
تشخيص اينکه چه زماني يک بلوک به ظرفيت مينيمم يا ماکزيمم خود رسيده مشکل ميباشد.
اعمال مربوط به تجزيه، ادغام و توزيع مجدد کليدها در گره هاي مختلف مشکل تر خواهندبود.
اسلاید 8 :
Loading a B+Tree
روش بهينه ايجاد ( loading) يک B+Tree چگونه است؟
براي تبديل يک فايل بزرگ به B+Tree بهتر است که:
از روش معمولي ايجاد رکورد ها به طور random استفاده نشود،
چون عملي بسيار طولاني و سنگين خواهد بود. (چرا؟)
روش بهتر اين خواهد بود که :
(1ابتدا، رکوردهاي فايل مرتب شوند ( sort )
(2سپس، رکوردهاي متوالي که مي توانند در هر بلوک قرار بگيرند دسته بندي شده و بطور يکجانوشته شوند. (يعني با يک I/O براي هر بلوک داده )
(3در ضمن separator هاي بلوک هاي متوالي به مرور جمع آوري شده و در حافظه نگهداري شوند و هر نود ايندکس پس از تکميل ظرفيت بطوريکجا نوشته شود. (يعني با يک I/O براي هر نود ايندکس )
اسلاید 9 :
Loading a B+Tree
مزاياي اين روش loading چيست؟
(1 نوشتن بلوک ها بصورت سري ( sequential ) انجام ميشود.
(2 فقط يک بار احتياج به خواندن داده ها ( و فقط داده ها ) ميباشد.
(3احتياجي به تجزيه، ادغام و توزيع مجدد کليدها در بلوک هاي مختلف نميباشد.
(4 درجه استفاده از ظرفيت بلوک ها (order) براحتي قابل کنترل است ودر صورت لزوم ميتواند حتي % 100 نيز تعيين شود.
(5 بلوک ها از نظر فيزيکي نيز مجاوريکديگر قرار مي گيرند و
(6 زمان seek هنگام استفاده مجدد کوتاه تر خواهد بود.
اسلاید 10 :
خواص انواع B-Tree و B+Tree
خواص مشترک انواع B-Tree و B+Tree کدامند؟
(1 همه از روش paged index استفاده ميکنند، در نتيجه:
با هر I/Oبلوک هاي بزرگي از مجموعه کليدها را به حافظه مي آورند،
فرم درختواره آنها broad & shallow يعني وسيع و با عمق (level) کم ميباشد.
(2 عمق آنها متوازن ميباشد. ( Height-Balanced Trees)
(3 به روش Bottom-Up و با اعمال تجزيه، ادغام و توزيع مجدد کليدها رشد ميکنند.
(4 کارآيي آنها با روش هاي تجزيه، ادغام و توزيع مجدد کليدها بين 2 تا 3نود بسيار بهتر ميشود.
(5 کارآيي آنها با روشهاي caching يعني نگهداري تعدادي از بلوک ها در حافظه بهتر ميشود.
(6 قابليت تطبيق با رکوردهاي با طول متغير را دارند.
